Alex Saez
IT Leader currently focused on AI, product engineering, and pragmatic software delivery

IT Leader currently focused on AI, product engineering, and pragmatic software delivery
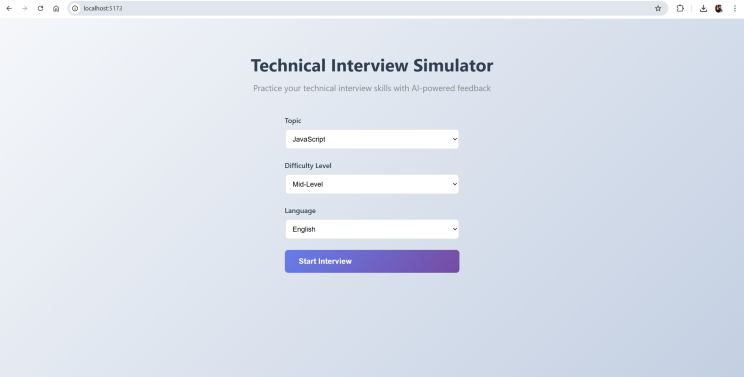
En mis tiempos libres, en casa, suelo probar aplicaciones que hagan uso de modelos modernos, para aprender haciendo y ver en qué punto están hoy los modelos open source locales. En una de esas pruebas se me ocurrió armar una prueba de concepto de un simulador de entrevistas técnicas, poniendo el foco en el uso de modelos de voz locales, tanto para speech‑to‑text como para text‑to‑speech.
La idea no era construir un producto terminado, sino explorar hasta dónde se puede llegar hoy con tooling open source y modelos que corran localmente, entendiendo bien sus límites y trade‑offs.
Para trabajar con modelos locales hoy en día hay bastante más solidez del lado de Python, principalmente por la cantidad y calidad de librerías disponibles. La librería de Transformers de Hugging Face es un buen ejemplo de esto. Por ese motivo elegí Python como lenguaje para el backend.
Como framework usé FastAPI, que para este tipo de proyectos me resulta cómodo, rápido de iterar y suficientemente performante.
En el frontend quería algo liviano y rápido, sin demasiada complejidad, así que opté por Vite con Preact. Para una prueba de concepto es una combinación más que suficiente y mantiene bajo el overhead.
Para esta primera versión me enfoqué en un sistema simple de preguntas y respuestas, descartando deliberadamente la conversación en tiempo real.
Esto fue una decisión consciente por dos motivos:
Los modelos locales actuales todavía toman bastante tiempo en procesar audio y generar respuestas.
Un esquema por turnos le da al usuario tiempo para pensar la respuesta antes de hablar, algo bastante realista en una entrevista técnica.
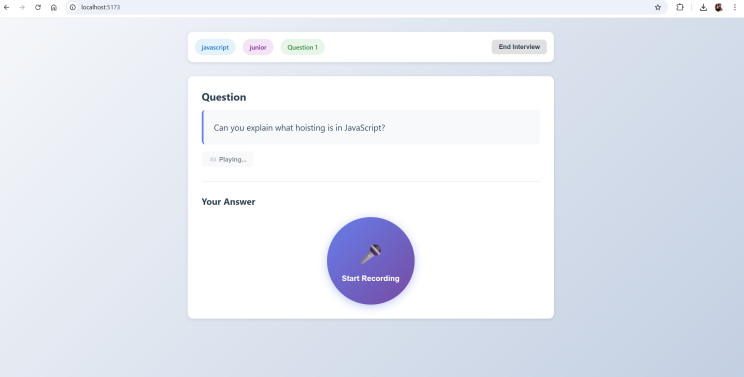
El sistema, entonces, funciona de manera secuencial: se presenta una pregunta, el usuario responde, se evalúa esa respuesta y recién después se avanza al siguiente turno.
Las preguntas de la entrevista fueron generadas con ayuda de un agente de codificación. Para esto utilicé Claude Haiku 4.5 y Claude Sonnet 4.5 a través de GitHub Copilot en VS Code. En este punto la idea era acelerar la generación de contenido y no tanto evaluar la calidad del modelo en sí.
Para las respuestas del usuario decidí usar un modelo de speech‑to‑text, en lugar de evaluar audio directamente con un modelo multimodal. Esto me pareció más eficiente por varios motivos:
Me permitía evaluar las respuestas usando un foundation model de texto, que suele ser más robusto.
Podía tener un log claro y de rápido acceso con las respuestas del usuario ya transcritas.
Para esto utilicé la librería faster‑whisper en Python.
Un detalle no menor que apareció en el camino es que faster‑whisper traduce el input al inglés si se fuerza el idioma inglés, lo cual no siempre es lo que uno quiere. En mi caso fue clave pasar correctamente el parámetro de idioma para evitar traducciones automáticas no deseadas.
La evaluación de las respuestas del usuario la hice con Claude Haiku, consumido a través de OpenRouter. OpenRouter me resulta muy práctico porque permite usar distintos modelos con una misma API.
Para esta prueba de concepto usé un modelo cloud, ya que la evaluación de texto no era el foco del experimento. Lo que quería testear principalmente era el uso de modelos locales de voz.
Donde más tiempo invertí fue en la investigación de modelos open source de text‑to‑speech que pudieran correr localmente.
El primer modelo que probé fue Bark de Suno AI. Suno es un proveedor bastante reconocido en generación de canciones, así que a priori parecía una buena opción.
Sin embargo, la versión de Bark disponible en PyPI está bastante desactualizada. La recomendación es usarlo directamente desde el repositorio de GitHub:
Incluso así, después de varios intentos no logré hacerlo funcionar correctamente. Todo indica que Bark está usando alguna funcionalidad de PyTorch deprecada, y no pude destrabar ese problema.
Luego probé SpeechT5 de Microsoft. Este modelo logró ejecutarse, pero cuando intenté agregar soporte para español (la idea era que el sistema funcione tanto en inglés como en español) me encontré con que simplemente no podía “hablar” en español de forma usable.
En ese punto decidí cambiar nuevamente y probé Coqui TTS, que sí soporta múltiples idiomas, incluido español. Desde el punto de vista funcional fue el modelo que mejor se integró al proyecto.
Aunque logré que todo el flujo funcionara de punta a punta, la realidad es que la calidad todavía no es aceptable para un uso real.
Tanto en speech‑to‑text como en text‑to‑speech, los modelos locales tienden a equivocarse con palabras técnicas, algo bastante crítico en un simulador de entrevistas técnicas. La velocidad es razonable, pero aun así el sistema tarda al menos 20 segundos en leer las preguntas y procesar las respuestas.
Con el avance del ecosistema open source es muy probable que en algún momento tengamos modelos locales de mucha mayor calidad, pero hoy todavía no estamos ahí.
Más allá de las limitaciones, rescato que aprendí bastante haciendo este proyecto. Entender de primera mano qué funciona, qué no y por qué, vale mucho más que leer comparativas teóricas.
Como próximos pasos, la idea es:
Armar una versión usando modelos cloud para speech‑to‑text y text‑to‑speech, para ver si se puede lograr un prototipo más funcional.
En una siguiente iteración, probar modelos orientados a conversaciones en tiempo real y evaluar qué tan viable es esa experiencia.
Por ahora, esta prueba de concepto cumplió su objetivo: explorar los límites actuales de los modelos de voz locales y ganar experiencia práctica en el proceso.